
Inactive Projects
- Time Series Benchmarking
- ARC: Abstraction and Reasoning Challenge
- Catan: Deep Reinforcement Learning
This project is about developing some standard benchmarking for temporal and spatiotemporal datasets which are increasingly riding the wave of deep learning performance boosts. There is a vast number of important problems which can be cast as a temporally structured problem, and being able to benchmark the growing number of specially designed architectures of increasing importance.
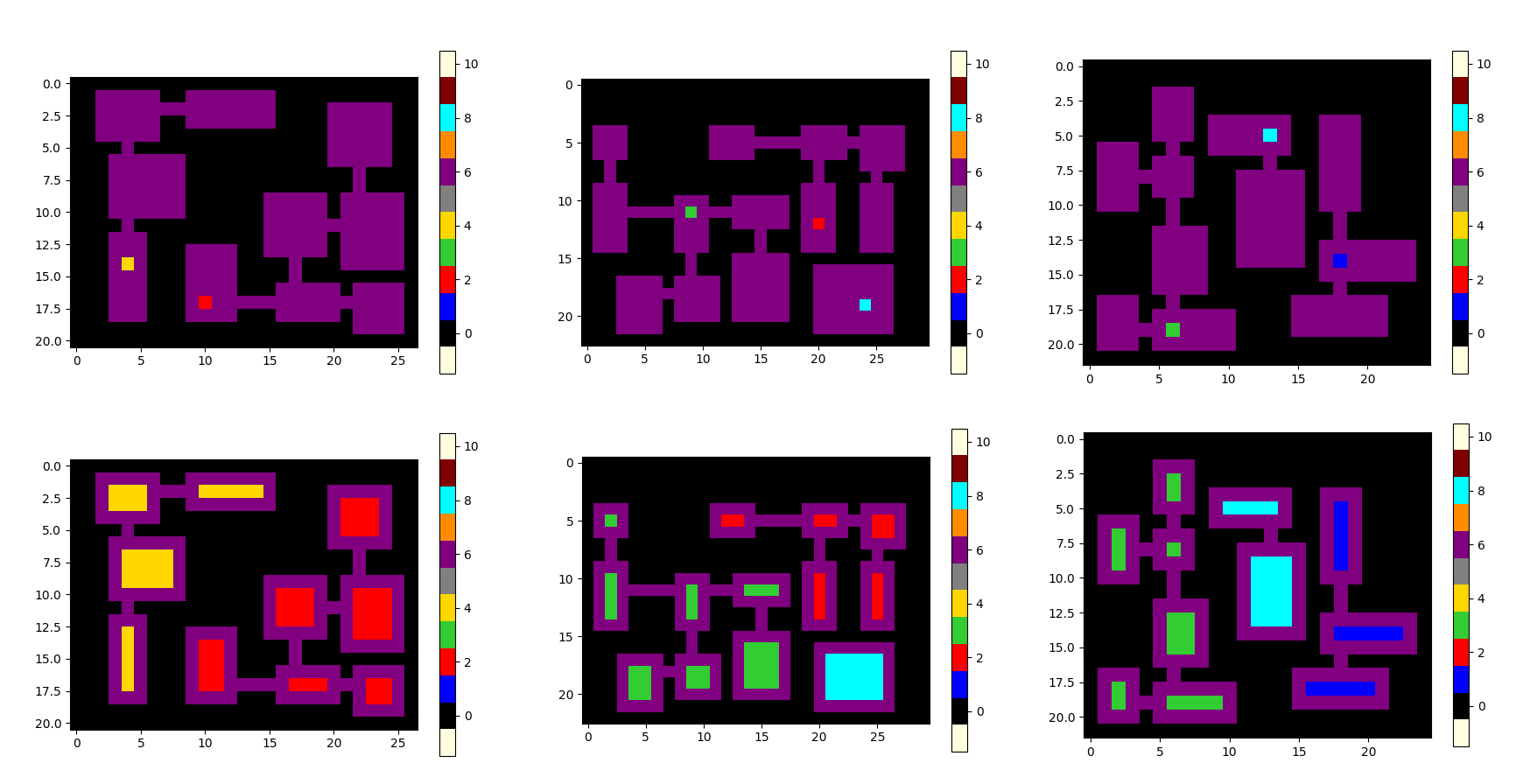
This project works on the ARC Challenge created by Francois Chollet designed to push the boundaries of current methods for artificial intelligence towards the generalizability and reasoning of human level intelligence, highlighting the shortcomings of current deep learning approaches. I am exploring the limitations of data-hungry methods through a systematic set of experiments in this simplistic domain.
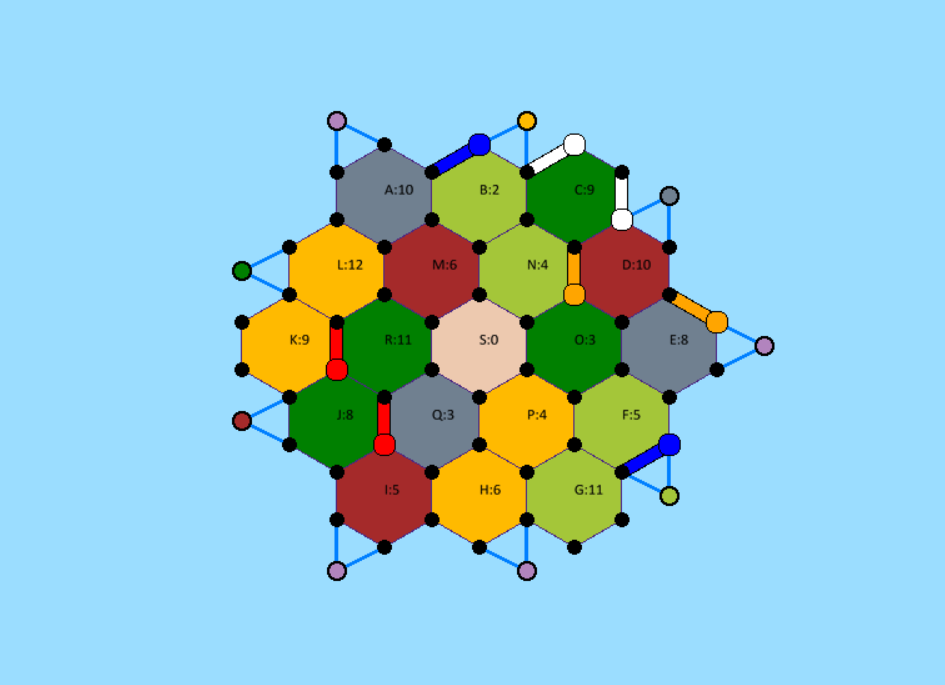
This project implements the board game CATAN which is a complex game involving planning, long-term decision-making, probabilistic value evaluation, and social trading amongst players. Next, this project will train reinforcement learning agents to play this complex board game. Currently, I have finished implementing the gameplay and am exploring different deep RL methods to solve this difficult problem.
Previous Projects
- League of Legends: Skill Prediction
- CNN Evalutation of Vector Field Visualizations
- Dataset Distillation for Privacy using GANs
- Classifying American Sign Language Letters from Images
- Exploring the Double Descent Curve in Deep Neural Networks
- The Effects of Size and Compression of Neural Networks
- Identifying Song Sentiment from Song Lyrics